
Solving Every Sudoku Puzzle Faster
Peter Norvig’s excellent essay Solving Every Sudoku Puzzle is a fascinating read, and I would highly recommend you read it (or at least scan it briefly) before you read the rest of this post.
Playing by the rules.
The program discussed in the article is able to solve every Sudoku puzzle by repeatedly applying two simple rules.
- If a square has only one possible value, then eliminate that value from the square’s peers.
- If a unit has only one possible place for a value, then put the value there.
These rules will make a lot of sense to anyone who has ever tried his or her hand at a Sudoku puzzle. In essence, they describe the most basic rules of the game. But there are puzzles that cannot be solved using these rules alone. When Peter’s program gets stuck (i.e. it cannot make any more progress based on these rules alone) it will apply a technique commonly known as ‘making an educated guess’.
As one who has dabbled in solving Sudoku’s puzzles before, I knew that Peter would probably have to resort to brute-force guesswork at some point. Some difficult puzzles simply require the human player or computer program to try different options and see if they result in a contradiction. Peter prefers to call this strategy ‘searching’, but that does not make the idea more compelling to me; or more efficient, for that matter. However, even though the puristic mathematician in me would like to solve every puzzle in a deterministic way, I have to concede that in some cases a little brute-force, applied at the right time and place, can arguably be quite elegant and actually improve performance.
I just think Peter is bringing out the Big Guns too early in the game.
When I built a Sudoku Solver some years ago, my aim was to build a program that could help a player identify possible next moves. This meant that the program should be able to give a reason for each of the values it assigned. At the time, for me, “I checked all the possible alternatives and they didn’t work” was not an acceptable explanation. So I spent most of my time searching for rules that I could use to deterministically find the solution to a puzzle.
Note: Like so many of my projects, I never got around to actually polishing the Sudoku UI and making the software useable to anyone but myself. Once the program was capable of solving most of the puzzles I could find, I lost interest and moved on.
I found that I could reduce most of the rules I came up with (and rules I found in Sudoku guide books) to two simple rules.
- If a square has only one possible value, then eliminate that value from the square’s peers.
- If a unit has only N possible places for values d1 to dN, then those are the only options in those places.
The first rule is identical to the first rule Peter uses; and when N is equal to one, the second rule is identical to Peter’s rule number two. But this more elaborate rule also works for other values of N.
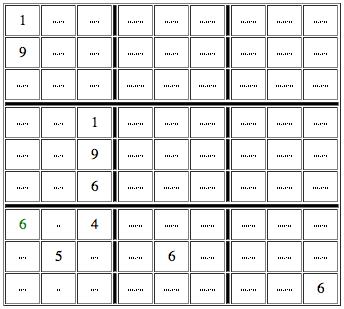
For example when N is two (see image). If there are only two places where the values one and nine are possible in a unit (the box in the lower left), then those values will have to be placed in those places (top and bottom middle column). As a consequence, even though we do not know which value goes in which place, we do know that other values (in the image six is the value to note) will not be possible, since placing them there would mean that either one or nine could not be placed in the unit at all. In the example image shown, this means we can be certain that six goes in the top left corner of the lower left box, because the only other option for six, the cell one to the right, is already occupied with either one or nine.
Wrestling the Python.
I wanted to see if my generalized rule number two could improve the (already impressive) performance of Peter’s program. I’d never worked with Python before, but that was no object. Peter’s programming and article are so clear it was relatively simple to adapt the logic to implement the generalized rule number two for the case where N = 2.
Note: My implementation is probably a bit crude. I’m open to suggestions. Never too old to learn.
First, I needed to alter the assign method so it can handle multiple possible values.
def assign(values, s, d):
"""Eliminate all the other values (except those in d) from values[s] and propagate.
Return values, except return False if a contradiction is detected."""
other_values = values[s]
for e in d: other_values = other_values.replace(e, '')
if all(eliminate(values, s, d2) for d2 in other_values):
return values
else:
return FalseThen, I added a condition to the eliminate method that checks for instances of rule two where N = 2.
## (2b) If a unit u is reduced to only N places for values d1 to dN, then
## those are the only valid options for those places.
## The following logic only works for N = 2, which is good enough for many
## sudoku puzzles and already improves performance over the original code.
elif len(dplaces) == 2:
# d can only be in two places in unit; find companion number
for e in values[dplaces[0]]:
if e != d and e in values[dplaces[1]]:
# ensure the companion number can also only be in two places
eplaces = [s for s in u if e in values[s]]
if len(eplaces) == 2:
# these two numbers are the only options for these two places
if not (assign(values, dplaces[0], d+e) and assign(values, dplaces[1], d+e)):
return FalseThat’s all there was to it. The adjusted program is able to solve all the same puzzles as the original, but should resort to educated guessing less often. The question is whether my crude implementation of this generalized rule will result in better performance. It is quite possible that checking for the additional deterministic constraint requires more computations on average than the existing brute-force approach, resulting in worse performance overall (despite the fact that it results in less guesswork).
Proof of the pudding.
I tested the two versions of the program on the 95 difficult puzzles used by Peter in his article. On my old MacBook, the original program reported requiring an average time of 0.04 seconds (27 Hz) and a maximum time of 0.18 seconds to solve these puzzles. The adjusted program was just under twice as fast on average with a time of 0.02 seconds (43 Hz). The maximum time improved more dramatically and proved more than twice as fast with a maximum time of 0.07 seconds.
I interpret these results to mean that the additional rule has a more pronounced effect on the time required to solve the difficult puzzles than on simple puzzles. Difficult puzzles that required quite some guesswork before can now be solved more easily, because of the additional rule. Simple puzzles are less affected. The average thus drops as a result of the significant reduction of the maximum time.
Reducing the need for brute-force searching improved performance. Still, there are puzzles that cannot be solved using this generalized rule. I’d be interested to see if anyone can come up with any additional (or more general) rules that would eliminate the need for guesswork altogether (or alternatively, prove that this cannot be done).
Update (januari 29th): Peter Norvig has kindly allowed me to share the modified version of his program. You can preview the code and download the source here. Thanks Peter!
Update (februari 5th): Okay. So maybe I was jumping to conclusions a little early in the game. Mea culpa.



