
Simulating Repeated Significance Testing
My colleague Mats has an excellent piece on the topic of repeated significance testing on his blog.
To demonstrate how much [repeated significance testing] matters, I’ve ran a simulation of how much impact you should expect repeat testing errors to have on your success rate.
The simulation simply runs a series of A/A conversion experiments (e.g. there is no difference in conversion between two variants being compared) and shows how many experiments ended with a significant difference, as well as how many were ever significant somewhere along the course of the experiment. To correct for wild swings at the start of the experiment (when only a few visitors have been simulated) a cutoff point (minimum sample size) is defined before which no significance testing is performed.
Although the post includes a link to the Perl code used for the simulation, I figured that for many people downloading and tweaking a script would be too much of a hassle, so I’ve ported the simulation to a simple web-based implementation.
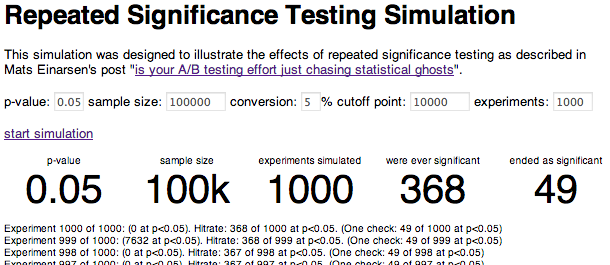
You can tweak the variables and run your own simulation in your browser here, or fork the code yourself on Github.



