
Written by Lukas Vermeer and Joshua Tankard.
List prices, referring to the price of products and services before discounts are applied, are a powerful lever at our disposal that can immediately impact business performance. For us, the right price is the one that simultaneously supports two crucial objectives:
- Delivering the best value for our customers and
- Optimizing the long-term financial return for our business
At Vista, we frequently optimize prices in response to changing conditions such as costs, customer preferences and the competitive landscape. We are also cultivating a culture of experimentation and amplifying the quality and quantity of our experimentation through our Experimentation Hub. Every change in list price could be considered a treatment condition in an experiment. As a natural consequence of this, we systematically measure the impact of price optimizations against our business objectives to make sure they are really delivering the intended value.
Previously, about 95% of price change experiments run at Vista were not A/B tests. And in fact, on our newer platforms, we will deliberately not build the capability to run traditional pricing A/B tests at all. In this post, we explain some challenges relating to list prices and more traditional modes of experimentation and we look into which testing capabilities we are building moving forward.
The challenge
Traditionally, A/B experiments are randomized at the user level and treatments are confined to changes in one part of a website or to a single channel. However, list prices are shown in many places and channels, and thus can penetrate many pages and channels at once.
Consistency of prices is extremely important for our customers. If users see one price before arriving on our site and another price later during checkout then they might be confused, or worse: disappointed and dissatisfied. A good test design would allow us to experiment with price changes on all parts of the site and all channels simultaneously.
Identifying the correct pages to run the test experience and tracking users accurately across multiple channels and testing tools can be very difficult, if not impossible. As a result, we would likely have to make compromises and exclusions to get a traditional user level A/B experiment for prices off the ground.
Although A/B testing is touted—often rightly so!—as the “gold standard” for experimentation, it can only be applied in the right conditions for the right experiment. We should not be willing to compromise the customer experience for the sake of better data. In the case of testing prices, traditional A/B testing might simply not be an option available to us if we are unwilling to compromise price consistency and the customer experience.

A solution
One alternative available to us is to use a quasi-experimental design such as an interrupted time series with a single point of intervention (informally known within Vista as a “pre-post test”). This has been a very popular approach within Vista, mostly due to its simplicity (simple to execute, if not analyze). Over 200 pre-post tests have been performed over the past year.
Whilst there has been a lot of investment and improvement in creating self-service tooling and automating machine learning driven baselines for these types of experiments, the fact that they are not fully controlled experiments means their usefulness is limited in terms of confidently measuring impact. Stronger assumptions are required and power is often limited.
Considering the importance of price testing, we wanted to find an approach that would improve upon these weaknesses, while at the same time not compromising our dedication to the user experience.
A better solution
Time-split experimentation (otherwise known as switchback / crossover / time-discontinuity designs) operates on the principle that instead of randomizing visitors or customers, we can randomize time-units into our control or test treatments instead. A time-unit in theory can be anything from a second to a year—or anything in between. In order to minimize impact on the customer experience and maintain sufficient power, the level of granularity we chose in this application is units of one day. During the experiment, some days will be control days, while others will be treatment days.

The randomization aspect of this approach to testing is important because if days are allocated manually within the experiment there is a higher chance of unintended confounding which would bias the results. At the same time, because there are strong weekly business cycles, we want to ensure that there are an equal number of each weekday (Monday, Tuesday, Wednesday, etc) in all treatment groups. We use simple blocking techniques to ensure that both requirements are met.

By the end of the experiment, treatment groups can be aggregated and compared (with some analytical techniques to further reduce some unwanted variance). This approach allows for testing pretty effectively on our biggest products—but there are still many products that may not be effectively testable in a reasonable timeframe
Testing as self-service
Time-split experimentation as a method is not new; and self-service experimentation has similarly been around for a while. But making time-split experimentation available as a self-service feature for list prices to non-specialists is not something we have seen applied previously.
Thanks to a partnership with Cimpress Technology, setting up a time-split experiment at Vista is now as simple as making a regular price change. Inside the new time-split experimentation module of the Pricing Manager Tool (PMT), the pricing specialist uploads their new price set, describes their hypothesis (broken down into motivation, description of change and expected results), and specifies the number of weeks the experiment should run. A separate tool, which will eventually be integrated into the PMT, has been developed that will help pricing specialists determine how many weeks are needed according to the chosen lead metric and minimum effect of interest.
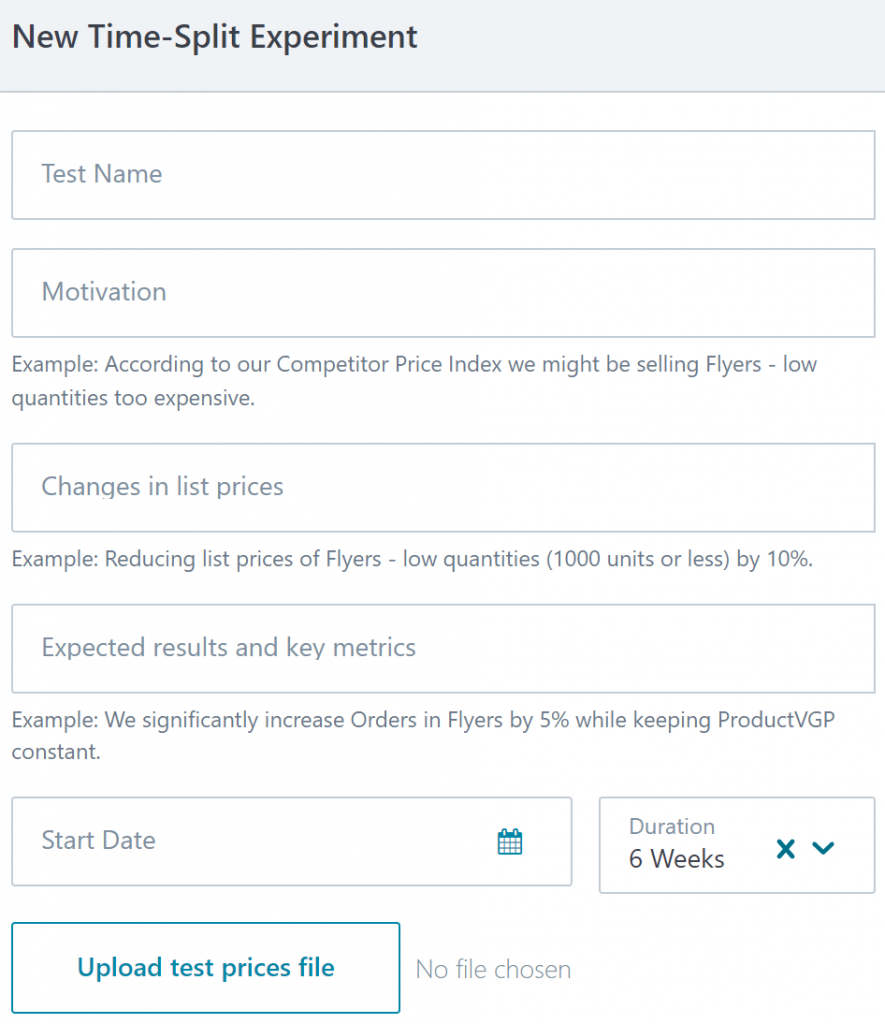
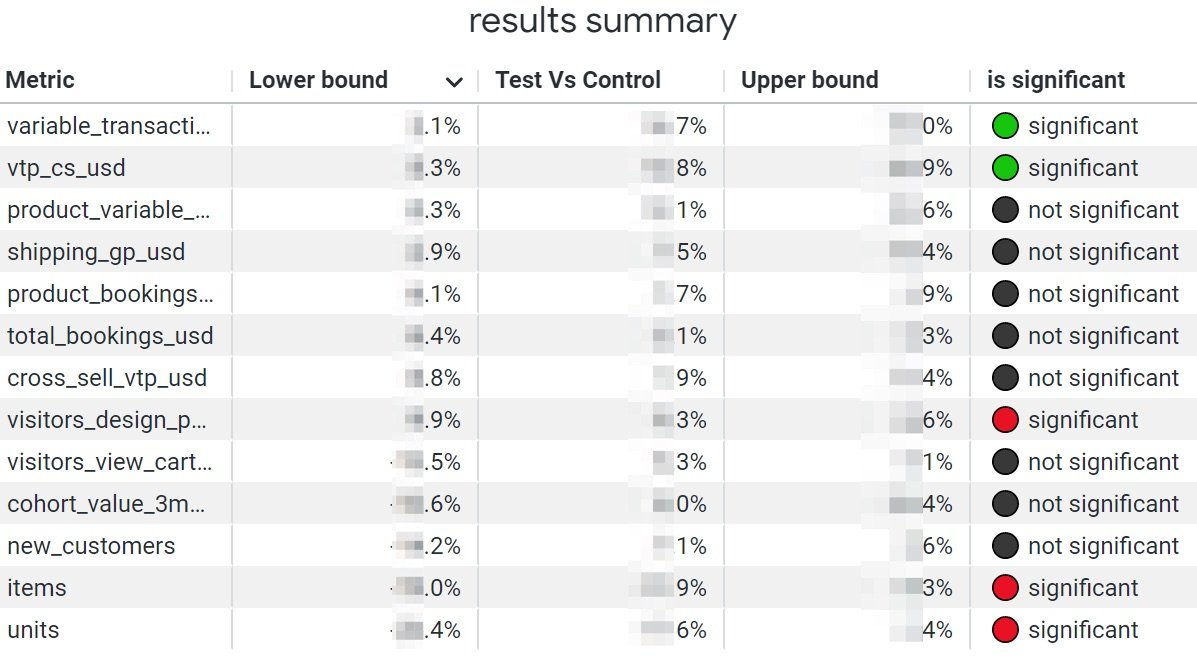
The analysis of the results of the experiment is also entirely automated using a Python script and a Looker dashboard. Time-split testing is therefore entirely self-service end-to-end, with no developers or analysts needed to perform a test. Gone are the days when tooling constraints and analyst availability limited our A/B testing to just a handful per year! Once a test is complete, the specialist can also take affirmative action and roll out the test prices (if successful) directly from inside the PMT.
Next steps
We are still early on in our journey towards time-split experiments. As with any new tooling and technology, there may be slow adoption to begin with as stakeholder’s confidence increases. Adoption is expected to ramp up once our users can see consistently reliable results (particularly compared to the best pre-post forecasting methodologies).
In order to further aid adoption, several A/A style tests have been launched. In these tests the test prices are exactly the same as the control. Some false positive results are to be expected, but overall these should remain within tolerable limits. This approach has several benefits:
- There is zero or minimal risk to the business as from the perspective of internal stakeholders and customers, nothing changes.
- It will hopefully increase user confidence when results align with expectations.
- Testing the Pricing Manager Tool to help identify any minor bugs in the price change scheduling that have not been caught in development.
- It will help us calibrate and further validate the analysis automation behind the scenes.
Once adoption and trust in the system increase, we have plans to further expand the scope of the kinds of price changes and treatments that can be tested. For example, by adding support for testing prices concurrently with a change in the user experience, or adding discounts on top of list prices.
Limitations of time-split experimentation
This article was written to promote the benefits of time-split testing for pricing but it would only be reasonable to mention some limitations for fairness. Some of these may be addressable in the future whilst others may not.
As mentioned previously, whilst time-split experimentation will help confidently measure and unlock large amounts of value in pricing, the statistical power is lower than that of A/B testing (limitations notwithstanding). However, neither approach to testing are powerful enough to help practically measure the impact for our smallest products and time-split will be orders of magnitude more powerful than pre-post.
Whilst A/B testing has issues with showing prices consistently to customers at any one point in time, time-split has to deal with the fact that every few days the prices will change for all customers. Whilst this helps overcome the consistency issues in one dimension, this may impact the experience for some customers in another dimension. This is one reason why the time-units are days, to limit any negative impact and reduce spillover effects between both treatments.



