
Understanding Mechanisms of Change in Online Experiments at Booking.com
Mediation Analysis to Disentangle Direct and Indirect Effects
Written by: Tolga Oztan, Zoe van Havre, Chad A Davis and Lukas Vermeer.
At Booking.com, one of the key ingredients to customer-centric product development isn’t just bright minds having great ideas, but collecting the evidence to support these ideas. We test each idea addressing a customer pain point via an A/B test using our in-house experiment platform. This platform is able to test thousands of changes simultaneously, with real customers, collecting data on the outcome within minutes of being implemented. However, as Booking.com grows to more countries, more languages, and our products grow in scope from hotels to other types of accommodations, cruises, car rentals, and more, our product development procedures must also become more flexible and more sensitive to the interactions of these many goals.
An A/B test (also known as a “randomised controlled trial”) helps us assess the causal effect of the implementation of an idea (from now on referred to as treatment) on some desired outcome. Even though we can never observe the outcome for a given person under both exposed and not exposed conditions — a problem known as the Fundamental Problem of Causal Inference — we can still get an unbiased estimate of the effect of the treatment on the intended population, referred to as the Average Treatment Effect (ATE). If the ATE was all we cared about, we would be done. However, at Booking.com, we care about two things:
- The ATE, the total effect of our treatment on the outcome variable
- The mechanism of change, how the treatment affected our visitors’ behaviour and, as a result, how the outcome variable changed.
While A/B tests are a powerful tool for estimating the overall effects of product changes on business metrics, they often fall short in explaining the mechanism of change. This becomes problematic when decision-making depends on being able to distinguish between the direct effect of a change or treatment on some outcome variable and its indirect effect via a so-called mediator variable.
In this post, we use a working example to explain the need for mediation analyses in online experimentation. We use simulated data to show how these methods help identify and estimate direct causal effects. We show that failing to take into account all confounders can lead to biased estimates, and we include sensitivity analyses to help gauge the robustness of estimates to missing causal factors.
Reducing ‘cancellations per visitor’
Cancellations due to unclarity around accommodation policies, facilities or prices lead to a bad customer experience, which we want to avoid as a general principle. In addition, cancellations make availability calculations more difficult for our accommodation partners and lead to a bad experience on their side as well. A confused, dissatisfied customer or partner is more likely to call our customer service, which also increases our customer service agents’ load.
We have teams working on solutions to address the pain points of customers and partners regarding cancellations. In one experiment, one such team might change the design of a page to bring more clarity to potential guests before they make a reservation, adding a text box containing an explanation of the property policies. Their goal is to make guests more aware of the prices around their trips, so that they have a lower chance of cancelling later, resulting in a reduction of the metric ‘cancellations per visitor’. We can represent such a scenario visually using a causal graph:

A graphical representation of a treatment affecting an outcome.
If the only goal was to reduce cancellations, the experimenter could go ahead and use the ATE to see if this was achieved, testing the difference between the average cancellations per visitor between the control and treatment group. However, this would never tell us how this result was achieved. The learning comes with understanding the mechanism of change, and teams need this understanding to explore other ideas or abandon those that don’t work.
Modelling the flow of effects
We encourage teams to monitor complementary metrics that can provide additional support for their hypothesised mechanism. For the example above, as the new information is displayed in a text box, a supporting metric might be if visitors hovered on the text box or not. We can extend the causal graph to include these supplementary metrics:
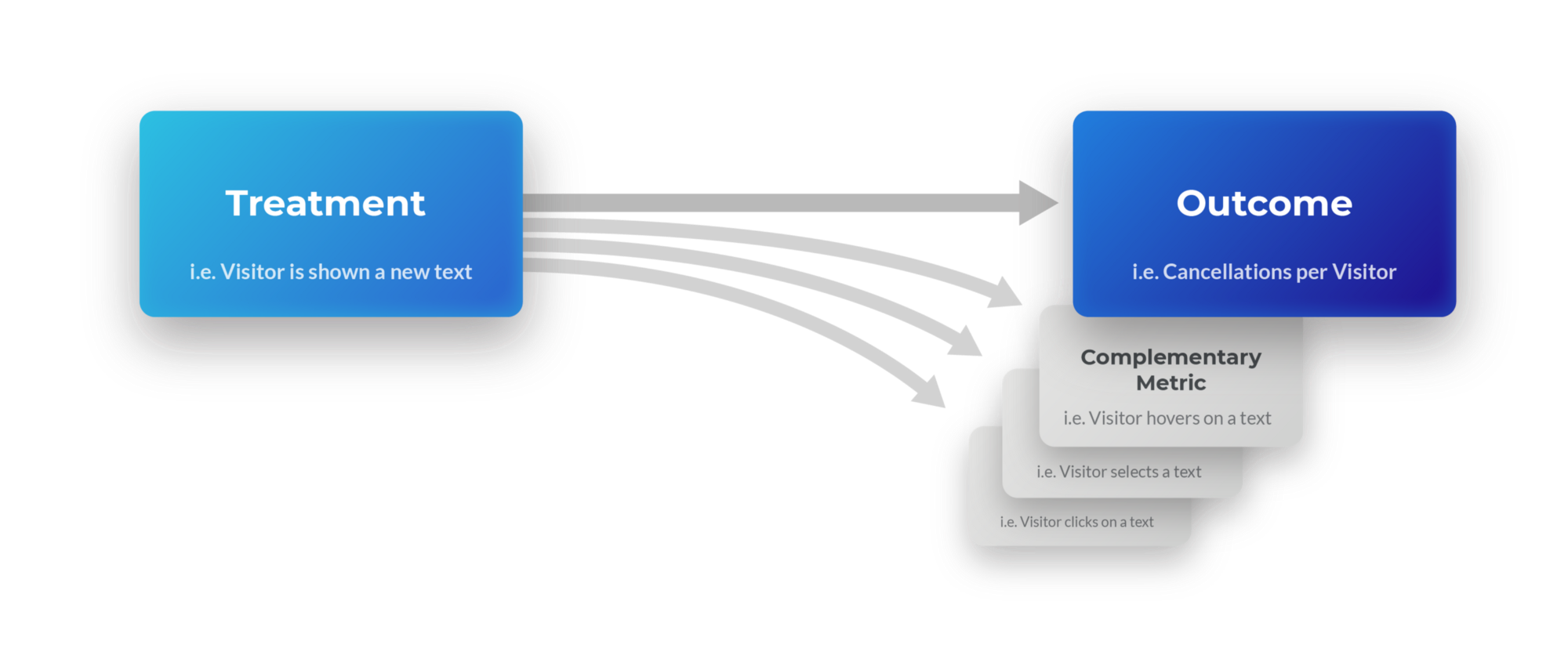
A graphical representation of a treatment affecting an outcome and several complementary metrics.
Here the team is explicitly checking one specific mechanism which is the reduction of cancellations complemented by a hover on the text box. If hovers increase and cancellations decrease, we understand the mechanism better. However, if cancellations change without the number of hovers changing, then either an unforeseen mechanism is at work or we’re dealing with a false positive. Either way, this additional insight can help the team better understand how their treatment is affecting visitor behaviour.
Direct & Indirect Treatment Effects
This approach gets more complicated when the metric that will help explain the mechanism is directly related to the outcome variable, while treatment is also expected to directly affect the outcome variable. For instance, if we observed a decrease in cancellations per visitor, but the number of bookings was also reduced. Did the reduction in cancellations originate from the new feature saving customers from making bookings, most of which would have been cancelled anyway, or did it inadvertently scare off previously satisfied customers from making bookings at all? We can express this mediation scenario graphically:
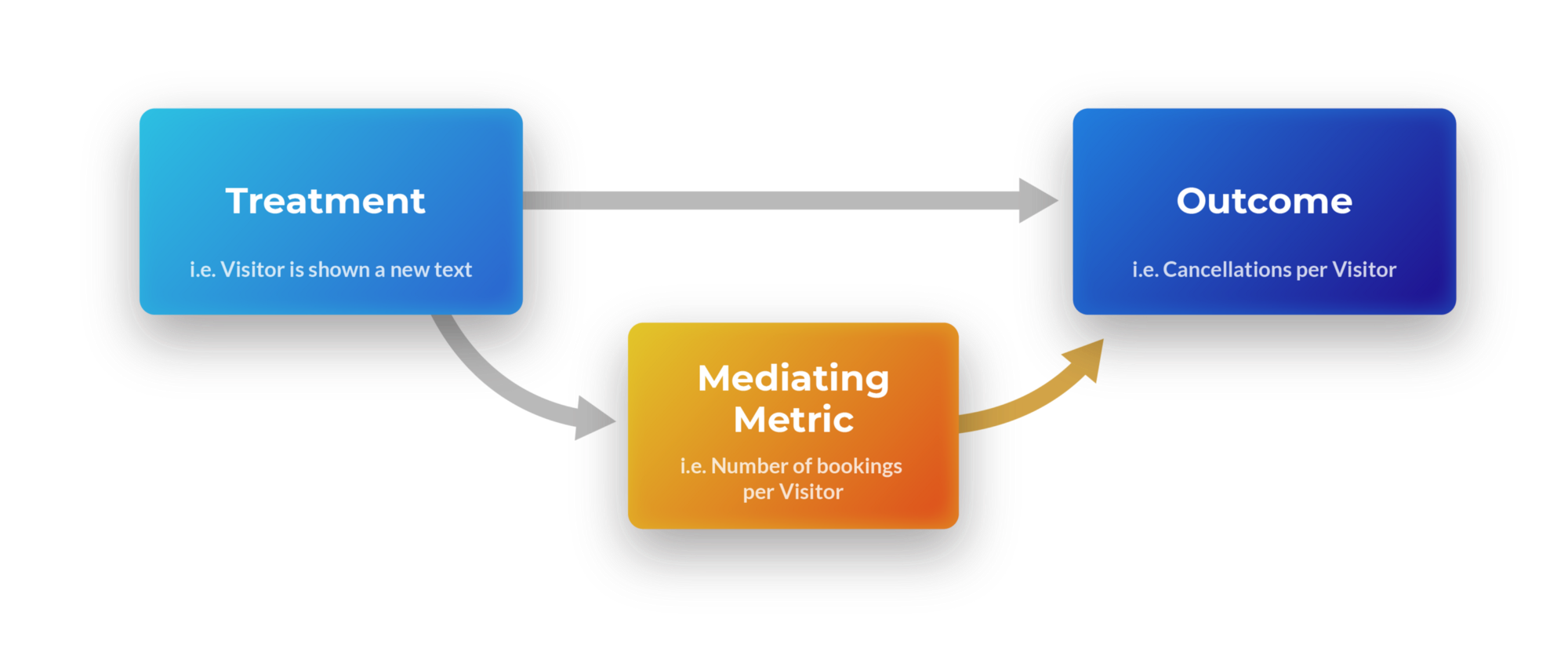
A graphical representation of a treatment affecting an outcome directly, as well as through a mediating metric.
In this case, Bookings is a direct parent of the child metric Cancellations, meaning any change in bookings will automatically cause a change in cancellations. If you have more bookings, you have more opportunities for one of the bookings to get cancelled. If you have fewer bookings, you have fewer opportunities for a cancellation to happen.
The Average Treatment Effect in this example can be broken down into two effects:

The Indirect Effect is the effect of treatment on cancellations via bookings and the Direct Effect is the effect of treatment on cancellations directly. A standard A/B test will only tell us the sum of these two effects (the ATE) which is a very crucial quantity. If cancellations increase beyond an amount that we can tolerate, they may not care if the increase is due to additional bookings or the treatment’s direct effect. However, in most cases, to be able to understand the mechanism and to be able to make a decision, we need to disentangle these two effects.
The trouble with confounders
Another lurking problem is that of known and unknown confounder variables. In the example above, imagine some visitors are business travellers. We can extend the causal graph with one confounder (‘is visitor travelling for business’):
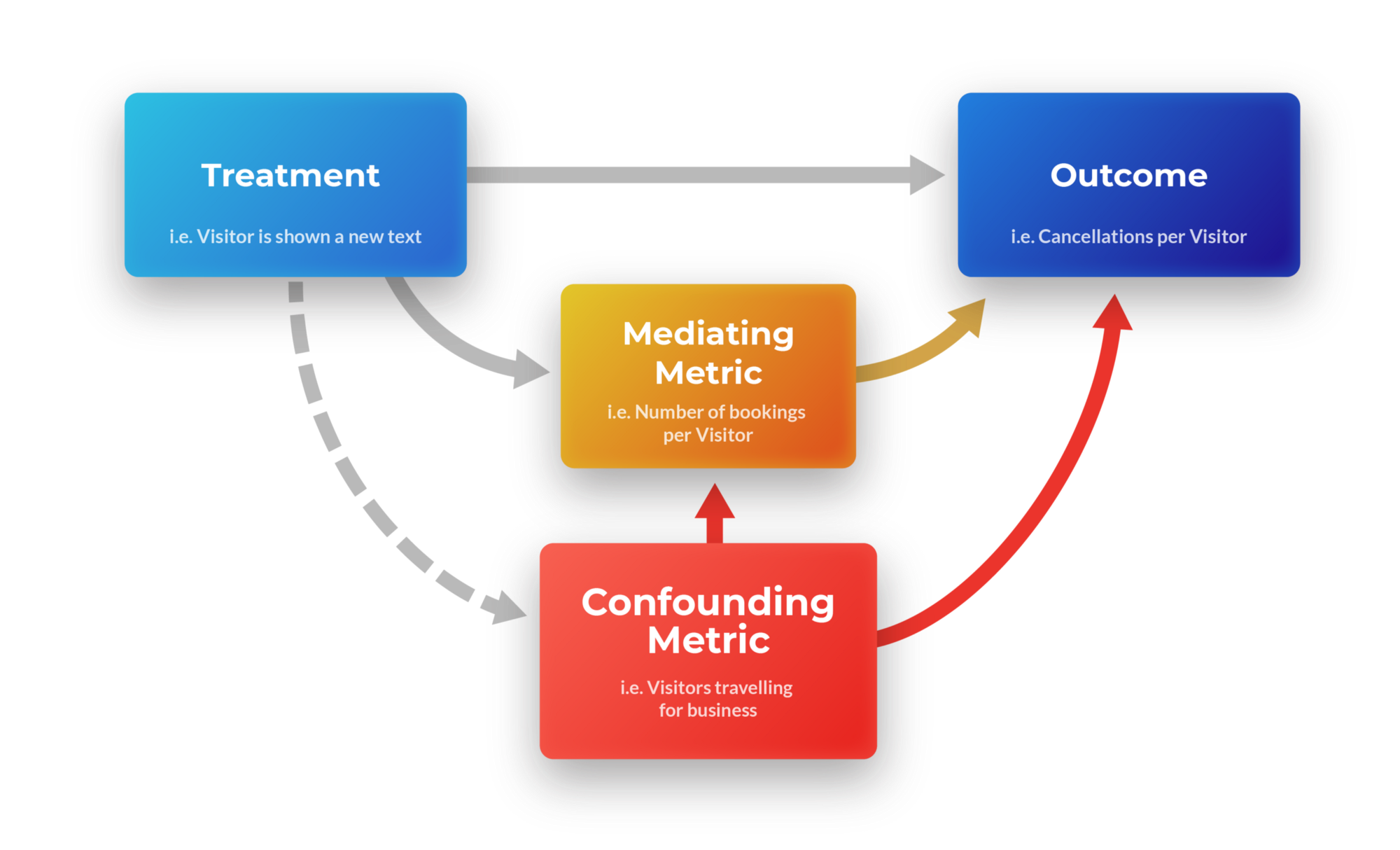
A graphical representation of a treatment affecting an outcome directly, as well as through a mediating metric and a confounder.
Confounders can add a layer of non-identifiability to the problem of interpreting the causal effect. While methods do exist which enable us to adjust for post-treatment covariates, the moment we do this, we lose the unbiasedness of the causal effect, unless we can control for all potential confounders. The reason for this is that the confounders and treatment are not independent conditional on the mediator variable, bookings.
By design, we randomise the visitors so that treatment and whether a visitor is a business traveller or not are independent. However, they are not conditionally independent. Imagine a scenario in which business visitors book more and also visitors in the treatment group book more. If we know how many bookings a visitor has, then knowing if they are in treatment or not would give us information about their likelihood of being a business traveller or not, and vice versa.
A method for dealing with confounders
The method we employ follows Imai et al.. Given a set of pre-treatment confounders X, we assume the following, known as the sequential ignorability assumption
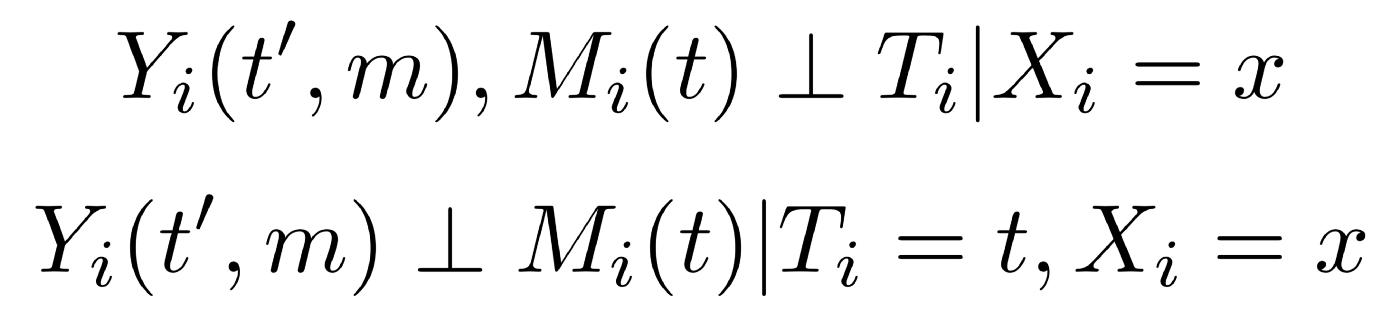
The first equation says that given a set of pre-treatment covariates X, treatment assignment T is independent of the potential outcomes and potential mediator values. The second equation says that given the same set of pre-treatment covariates X and the actual treatment value T the mediator potential outcome is independent of the potential outcome.
The first equation is guaranteed to hold by design, as the context we work in is randomised online experiments. The second equation says the mediator variable is ignorable conditioned on the pre-treatment confounders X. Looking at it from the perspective of Directed Acyclic Graphs notation, we assume that all the back-door paths we may be opening by conditioning on the mediator variable will be blocked by the set of pre-treatment variables X. If this assumption holds, then the direct and indirect effects of treatment on the outcome variable are identified and we can estimate them non-parametrically.
For the estimation of causal effects, we use two-stage modeling as proposed in Imai et al. The form of these models are not important as long as sequential ignorability holds; so we use generalized linear models that are suitable for the outcome variables.
Testing the method with simulated data
We simulated 100,000 data points with one pre-treatment confounder, whether a visitor is a business traveller or not, where half the visitors are randomly assigned to treatment and half to control groups and within each group, the probability of a visitor being a business traveller is 0.4. On average a business traveller makes one booking while a non-business traveller on average makes also one booking, draws coming from Poisson distributions. The treatment adds two more bookings for business travellers but doesn’t affect bookings of non-business travellers. In addition, treatment has no direct effect on cancellations; therefore, cancellations per booking stays the same for each group; 14% for business travellers and 7% for non-business travellers, drawn from binomial distributions with said probabilities.
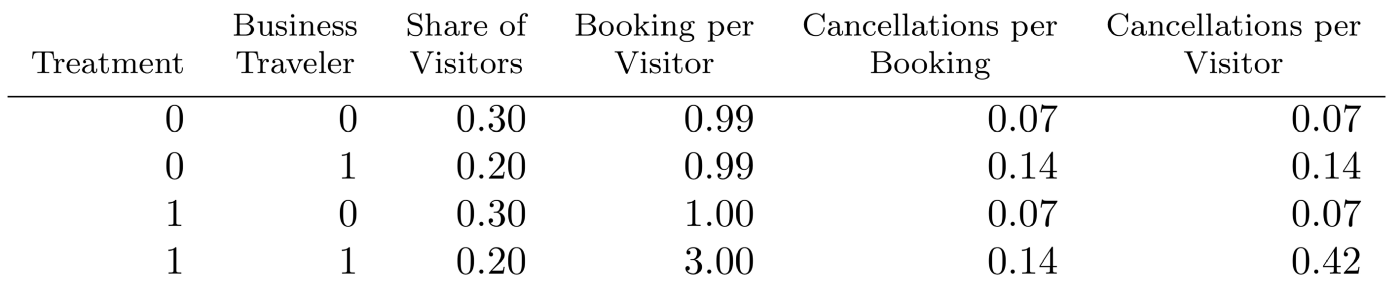
Simulation parameters.
We can see that the treatment has no direct effect on cancellations, as the cancellation rates per booking stay the same for the subpopulations. All the treatment does is make business travellers book more, from 1 booking per visitor on average to 3 on average. In this scenario, adding the number of bookings as a covariate in a regression model yields a positive regression coefficient for the effect of treatment on cancellations even though there is no direct effect of treatment on cancellations. Since there is a pre-treatment confounder and treatment and bookings are not conditionally independent, this approach gives a biased result. However, using the two-stage method and including the pre-treatment confounder in the models, we get direct effects close to zero (as expected).
We can also look at the point estimates for no adjustment, adjustment in a linear regression, and two-stage model results. (Here, we assume the experiment was run for 30 days, in order to bring the point estimates down to familiar per day units.)
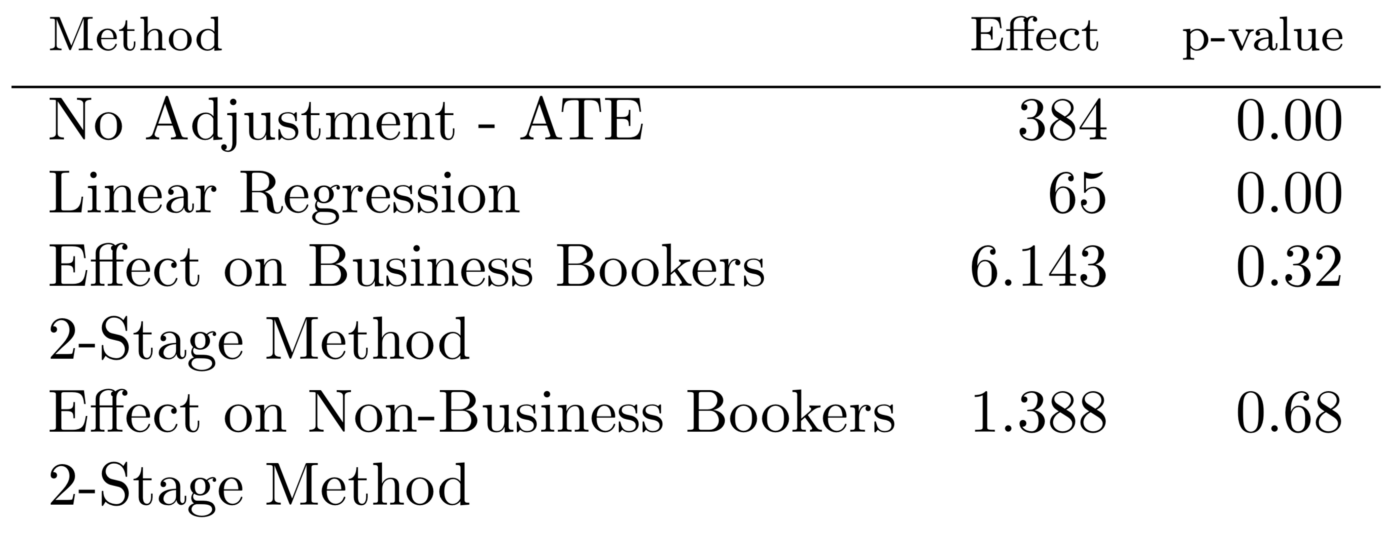
Direct effect of treatment on cancellations per day.
Next, we do a sensitivity analysis to see how robust the point estimates are to missing covariates. Data can never tell us whether we have successfully taken into account all pretreatment confounders. However, a sensitivity analysis can tell us how robust the estimates are. In our simulation data, we know there is only one pre-treatment confounder. So we expect the estimate to be quite robust when we include this variable in our models, and not robust when we omit it.
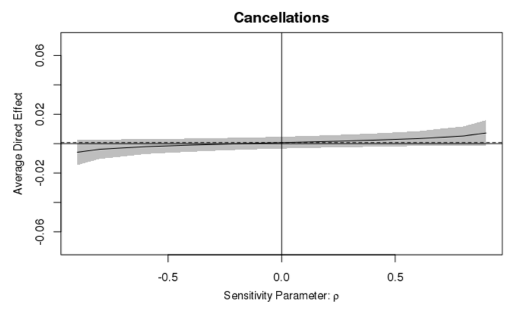
Sensitivity plot for direct effect including confounder.
This shows how the direct effect of the treatment on cancellations changes with the correlation of the error terms of stage 1 and stage 2 models when we include the pre-treatment covariate. Observe that even when the correlation term ρ on the x axis is at the extremes, -0.9 and 0.9, the 95 percent intervals still include 0, meaning we can never conclusively conclude that the effect is non-zero. On the other hand, when we omit the pre-treatment covariate, business booker, the conclusions change drastically depending on the value of ρ; as shown here:
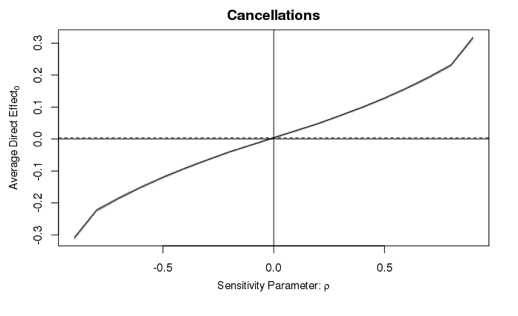
Sensitivity plot for direct effect omitting confounder.
In summary, A/B testing allows for rapid customer-centric product development, but is likely to produce biased direct effect estimates, as the method cannot account for confounders, nor identify missing confounders. This leads to decisions being governed by hidden factors, which will at best inject randomness into the decision making process (costing time and effort), and at worst erode the quality of a product. For example, in the hypothetical scenario above, naive use of standard A/B testing might lead to a product better tailored for business travellers, and by consequence shrink our customer pool significantly.
If identifying the mechanism of change is important for decision making, then we suggest:
- using multiple experiments to replicate findings and protect against false positives,
- measuring important health metrics, as well as metrics known to be related (causally) to the outcome (and to include these in the model as demonstrated), and
- performing a sensitivity analysis to check for missing confounders.
We encourage experimenters to always interpret results in context; making decisions which keep in mind the big picture, the mechanism of change, and the long term impact on customers.
Acknowledgements
This post was based on a paper presented at the 2018 Conference on Digital Experimentation CODE@MIT. These ideas were greatly influenced by our work on the in-house experimentation platform at Booking.com, as well as conversations with colleagues and other online experimentation practitioners. In particular, this work would not have been possible if not for the relentless challenging by raphael lopez kaufman. Causal graph figures were crafted by our amazing designer Alimsky Sergey. Thanks also to Lucas Bernardi and Steven Baguley for their inputs.



